


Nvidia's Margins May Be Safe
Why 90% margins on GPUs don't necessarily mean 90% margins on total cost of ownership.

TLDR:
Networking costs 15-30% of the cost of an AI chip cluster, so even if a GPU is 10X cheaper, the total cost of compute only becomes 2-4x cheaper.
If the performance is lower than nVidia, then you need more chips, which increases network costs! So if you try to sell an AI chip that’s 2x slower than nVidia, but 10X cheaper, then the need for more networking results in you costing more than nvidia!
Moving data, not computation, is often the biggest contributor to overall performance and cost.
This doesn’t mean that beating nvidia on performance is necessary, but it does mean that AI chip startups need to think about the network, and more broadly the total cost of ownership in their value pitch.
GPUs Prices Matter Less Than People Think
Jensen Huang recently said that nVidia's GPUs were “so good that even when the competitor's chips are free, it's not cheap enough." - Jensen Huang says even free AI chips from his competitors can't beat Nvidia's GPUs | Tom's Hardware
Jensen is exaggerating, but there is a kernel of truth.
People see nvidia’s 90%+ margins and see this as an obvious opportunity for margin compression.
But, this overfocus on the GPU’s price overlooks the total cost of ownership, which can often result in cheaper chips costing more overall.
How can a cheaper chip cost more overall??
The answer lies in the total cost breakdown for an AI chip cluster.
Although the GPUs are the biggest cost contributor, networking costs are also significant, as is power.
Many startups have made the pitch that they will reduce the cost of an AI chip, even if the individual performance of a chip is lower.
(since multiple chips can be connected together)
Examples include startups like Graphcore, which opt against using HBM memory to reduce costs (Graphcore Colossus Mk2 IPU).
Unfortunately, when the total cost is brought into account, this fades.
Ultimately, this matters significantly for nvidia’s margins. If the margin on a GPU is less of an impact to the customer’s costs, then the desire to move away from nvidia goes down greatly.
Although I focus on networking costs, there are other costs here like power, CPU overheads, node memory costs, etc, which I’m leaving aside.
Doubling the number of chips may not be trivially possible, e.g. doubling the number of chips may force increased use of tensor parallelism, which may cause MFU (compute utilization %) to drop- causing $/perf to go up! I neglect this for this article, but this goes to further my point.
Network Cost Analysis
So how much does the networking cost contribute to the overall system?
I’ve used two reference points: Nvidia’s GH200 system for their latest SuperPODs, and Meta’s reported network parameters.
Both represent different design points, although I think the GH200 is more realistic.
At the very least, LLM inference has much greater demands on the network, meaning that the GH200 network parameters are realistic for inference.
GH200 Network Parameters

An Overview of NVIDIA NVLink | FS Community
Announcing NVIDIA DGX GH200: The First 100 Terabyte GPU Memory System
In this case, we have (at least), 1800 gbps of injection bandwidth per GPU, which with optical cable costs of $600/100 gbps, for a cost of $10,800 per GPU!
Meta’s Network Parameters
You might object that the GH200 is overbuilt from a network perspective, and that Meta’s reported network costs are more reasonable.
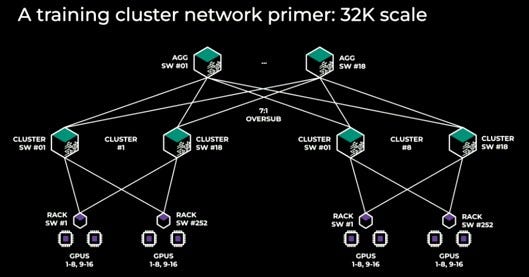
Given a tapered fat-tree topology as reported by Meta:
We’ll assume that you need an average of 2 links for each GPU, so 2x active optical cables at 200gbps per GPU. This is a total AOC demand of 400 gbps. Assuming a cable cost of $600 per 100G for AOCs, that’s $2400 per GPU.
The switch costs are another ~$200 per GPU (19 * 8 switches for 32K GPUs).
Even in this case, the cost of the networking is as much as the cost of the GPU itself (removing nvidia’s margin).
Watch: Meta’s engineers on building network infrastructure for AI
Cost Comparisons
There are two axes here for the case studies:
GH200 vs Meta network parameters
The GH200 is a higher BW network, which may not be needed for all workloads
Same performance vs 2x worse performance
Whether the proposed zero-margin AI chip has the same performance as the Nvidia GPU or is 2x worse.
The most likely case is Case 2: 2x worse performance, GH200 network parameters. In this case there’s only a 14% savings, which is easily wiped out when the total costs are taken into account.
Case 1: Same Performance, GH200 Network Parameters
Using a simple TCO Breakdown:
Nvidia Cluster:
GPU: $20K
Power and power equip: $2K
Networking costs: $10K
Total: $32K
Non-Nvidia Cluster:
GPU: $2K
Power and power equip: $2K
Networking: $10K
Total: $14K
~2.3x savings
Case 2: 2x Worse Performance, GH200 Network Parameters
Using a simple TCO Breakdown:
Nvidia Cluster:
GPU: $20K
Power and power equip: $2K
Networking costs: $10K
Total: $32K
Non-Nvidia Cluster:
GPU: $2K x 2
Power and power equip: $2K x 2
Networking: $10K x 2
Total: $28K
14% “savings”...
Case 3: Same Performance, Meta Network Parameters
Using a simple TCO Breakdown:
Nvidia Cluster:
GPU: $20K
Power and power equip: $2K
Networking costs: $2.6K
Total: $24.6K
Non-Nvidia Cluster:
GPU: $2K
Power and power equip: $2K
Networking: $2.4K
Total: $6.6K
~3.7x savings
Case 4: 2x Worse Performance, Meta Network Parameters
Nvidia Cluster:
GPU: $20K
Power and power equip: $2K
Networking costs: $2.6K
Total: $24.6K
Non-Nvidia Cluster:
GPU: $2K (x 2)
Power and power equip: $2K (x 2)
Networking: $2.4K (x 2)
Total: $13.2K
Less than 2x savings!
Conclusion
Although there are savings, even accounting for networking costs, in general the margin is quite small. Especially for the cases which assume the GH200’s network parameters, which is likely representative of the most valuable workloads (and certainly in the future).
This is bad news for startups like Graphcore or Tenstorrent, which have ~2-4x lower performance in each chip, and hope to make it up by being much cheaper.
The key point though, is that Nvidia’s margins may not matter as much as people think when it comes to the question of “will nvidia face competition?”. Margin compression may be less relevant when the total system costs are taken into account.
As always, in computer architecture:
Amateurs study compute, professionals study data movement.
Cable costs
We assumed a cable cost of $600/100 gbps for active optical cables. How did I arrive at this conclusion? It’s hard to get absolute numbers, but I relied on the following (public!) sources.
Sources:
[2209.01346] HammingMesh: A Network Topology for Large-Scale Deep Learning
(see Appendix)
Analyzing Network Health and Congestion in Dragonfly-based Supercomputers
Somewhat outdated since it’s from 2015, but copper prices aren’t exactly going down.
Trade-offs to Consider with DACs, AECs and AOCs
Relative costs, but can use this as another reference point
Active Electrical Cables (AECs) - Longer Reach & Greater Flexibility at Lower Cost
Note
This article doesn’t represent the views of Volantis, and the numbers in this article are based on purely public information.
Some of these numbers are wrong, but the conclusion is directionally accurate.